Supervised vs Unsupervised Machine Learning: A Comprehensive Guide

Machine learning has revolutionized industries, but understanding the differences between supervised vs unsupervised machine learning is crucial for success. The world is getting smarter every day and the primary reason behind this is advanced machine learning and artificial intelligence algorithms. Getting personalized recommendations on streaming platforms, automated workflows, and advanced medical diagnosis, what do you think behind all this? Yes! machine learning is backing everything.
Machine learning enables computers to learn from data and make decisions without being programmed. Additionally, if we dig deep, two fundamental approaches drive this field: supervised learning and unsupervised machine learning.
Well, are you not aware of these concepts? Don’t fret as in this article, we’ll talk about supervised and unsupervised learning, their key differences, real-world applications, and when to use each. Let’s dive in and explore machine learning together comprehensively.
Table of Contents
What is Machine Learning?
Before we dig deep into this article, it is important to understand what machine learning is. Generally, you can say that it is the subfield of artificial intelligence that allows systems to learn from data and improve their performance over time without explicit programming.
Moreover, machine learning, by analyzing patterns and making predictions, has led to cutting-edge technologies such as recommendation systems, recognition systems, and autonomous cars. Isn’t it crazy?
Simply put, machine learning turns data into actionable insights, making it a backbone of modern technology and innovation.
Overview of Supervised vs Unsupervised Machine Learning
Machine learning can be broadly classified into two main categories:
- Supervised Learning: This approach consists of labeled datasets that allow systems to predict inputs to outputs. It is best suited for tasks like classification and regression.
- Unsupervised Learning: Unlike the former, this approach focuses on discovering patterns and relationships in unlabeled data. It is ideal for applications like clustering and dimensionality functions.

Importance of Understanding the Difference
The current state of automation and innovation makes one thing clear: these models are going to become more sophisticated. Supervised and unsupervised learning serve as the foundation of various AI applications, yet they differ significantly in how they process and analyze data.
Understanding the major difference between these two approaches is really critical. It will not only help you select the right approach but also optimize the performance of machine learning systems.
Moreover, choosing between these two learning models depends on the type of data you have and the problem you’re trying to solve. This knowledge is important for businesses looking to improve strategic decision-making, professionals building data-driven solutions, and anyone who wants to work with artificial intelligence.
Supervised Learning and Unsupervised Learning at a Glance
Here is a quick comparison of the key differences between supervised vs unsupervised learning:
|
Aspect |
Supervised Learning |
Unsupervised Learning |
|---|---|---|
|
Definition |
Learning from labeled data where input-output outcomes are defined before |
Learning from unlabeled data to analyze patterns and structure |
|
Goal |
Minimize prediction error and generalize from training data |
Discover hidden structures or relationships in data |
|
Examples of Algorithm |
Linear regression, Logistic Regression, Decision Trees, Support Vector Machines (SVM) |
K-Means Clustering, Hierarchical Clustering, Principal Component Analysis (PCA) |
|
Accuracy |
Generally more accurate due to clear training signals |
It may require more post-processing to evaluate the results |
|
Complexity |
Simpler to interpret |
Complex and harder to interpret |
|
Applications |
Spam detection, fraud detection, house price prediction |
Customer segmentation, anomaly detection, recommendation systems |
What is Supervised Learning?
Let’s discuss supervised learning in detail. It is a subset of machine learning in which models are trained using labeled data. Particularly, this learning is more focused on learning the correspondence between input and output data. This allows the algorithms to learn a mapping function that evaluates outcomes for new data. It is mainly used for regression and classification tasks.
For example, consider a labeled dataset of shapes. The input would be images of shapes and their labels. For the output, each image is tagged with its crossing shapes image, such as a “rectangle”, “triangle”, or “square”.
The key characteristics include:
- Labeled Data: Training data includes both input variables (X) and output labels (Y).
- Predictive Modeling: Emphasize making predictions accurate.
- Feedback Loops: Errors during training help the model improve iteratively.
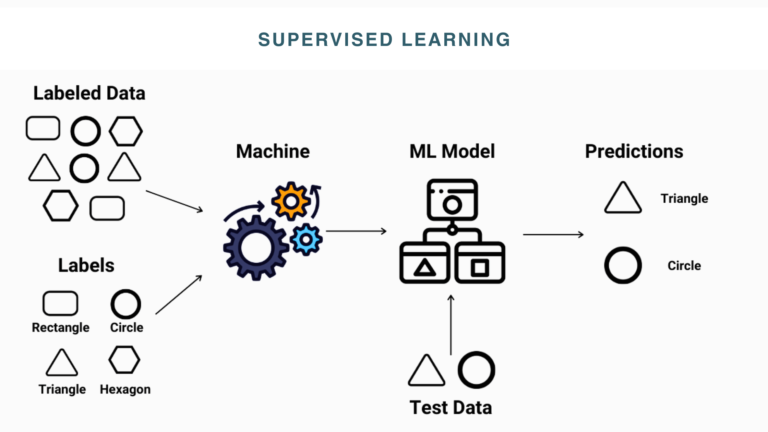
How Supervised Learning Works
Supervised machine learning techniques follow a systematic approach to training data to make accurate predictions. Here’s how it works:
Step 1: Training Phase
- At first, the algorithm is given with labeled data, where input data is paired with the correct output (e.g., images of animals labeled as “cat” or “dog”).
- After that, it learns to recognize patterns or relationships in the data by mapping input (features) to their comparable outputs (labels).
- Additionally, the model also adjusts its parameters to minimize errors using techniques such as gradient descent in this phase.
Step 2: Model Evaluation
- Once the model is trained, its performance is tested on a separate dataset, often called the validation set.
- To determine its output results, the model’s performance is measured using various metrics, such as accuracy, precision, recall, or mean squared error (MSE).
- The evaluation process helps ensure that the model is not overfitting and generalizes accurately to new data.
Step 3: Prediction Phase
- After training and evaluation, the model is deployed to make predictions on new and unseen data.
- For instance, the model is shown with the image of an animal to identify it whether it is a cat or a dog based on learned patterns.
Types of Supervised Learning
If we further break, supervised learning is divided into two main types based on the nature of the output variable: Regression and Classification.
1. Regression
Regression is a type of supervised learning that focuses on predicting a continuous or numeric value. In this type, the model learns the relationship between the input features and the continuous variable during training.
Key Features:
- Output is a continuous value, such as temperature, price, or time
- Helps to evaluate trends, future outcomes or estimate quantities
- Example metrics: Mean Squared Error, Root Mean Squared Error
Real-World Examples:
- Most commonly, it is used for predicting house prices based on location, size, and amenities.
- Evaluating stock prices using historical data.
- Estimating delivery time for package arrival based on distance and traffic.
2. Classification
Classification as the name suggests is a type that focuses on categorizing the data into predefined sets, or classes. In this approach, the model learns to link the correct label to the input data by identifying patterns during training.
Key Features:
- Output is classified as “spam” or “not spam”, “accepted” or “denied.”
- Suitable for problems where the goal is to group data into categories.
- Example metrics: Accuracy, Precision, Recall, F1 Score
Real-World Examples:
- The most common example is email spam detection; classifying emails as spam or legitimate.
- It is also used in disease diagnosis, such as identifying diseases based on patient symptoms or test results.
- Moreover, in fraud detection, it is used to spot fraudulent transactions in financial systems.
Common Algorithms Used in Supervised Learning
- Decision Trees: It is a tree-structured model that divides data into branches based on feature value. It is beneficial and efficient for both regression and classification tasks.
- Neural Networks: This is one of the most popular supervised learning algorithms typically inspired by the human brain and designed to handle complex relationships in data, such as image recognition and language translation.
- Logistic Regression: It is mainly used for binary classification problems and is beneficial for predicting the probability of outcomes like “yes/no” or “0/1”.
What are the Key Applications of Supervised Learning?
Supervised learning that is trained on labeled data has a wide range of applications across industries as it is the most straightforward and effective. Here are some of its key use cases:
It is Widely Used in Fraud Detection
Supervised learning models are used to analyze transaction patterns to find out any fraudulent activities. This enhances security and minimizes financial loss.
For example, in banking, algorithms like Logistic Regression or Random Forest are run to identify uncommon patterns in resource allocation or unauthorized transactions.
It has Major Use Cases in Image Recognition
Supervised learning classifies images into predefined categories by recognizing visual patterns and features. This is beneficial in healthcare, autonomous vehicles, and photo tagging.
For example, surveillance cameras recognize faces and identify objects in photos using Convolution Neural Networks.
It can be used for Predictive Analytics
Predictive analytics means you can forecast future trends based on previous and historical data. By gaining data-driven insights, businesses can make informed decisions and optimize strategies.
For instance, predicting customer churn in telecom, anticipating sales in retail, or demand forecasting in supply chains.
Advantages and Disadvantages of Supervised Machine Learning
While supervised learning has many advantages, it also has some limitations. Let’s discuss some of the pros and cons of this type of learning.
Benefits | Challenges |
It is highly accurate when trained on quality labeled data. | Requires a large amount of labeled data, which can be expensive and time-consuming. |
It solves a wide range of problems, from classification to regression. | It may have a potential of overfitting risk. |
Many supervised models offer insights into the data relationships | Training supervised models can be computationally expensive. |
Widely used in crucial applications such as fraud detection, medical diagnosis, and more | Performance can downgrade when applied to areas somehow different from the training data. |
What is Unsupervised Learning?
Unsupervised learning, totally different from the former, is a type of machine learning that learns from unstructured or unlabeled data. In simple terms, the data don’t have any predefined categories or labels.
Well, this type of machine learning is geared toward discovering patterns and relationships in the data without training or direct guidance. Moreover, it is used to group cluttered information and sort them based on similarities, patterns, and differences without any prior training.
For instance, in unsupervised learning, you will input raw data such as different shapes, and get the labeled and categorized data like “Triangles” and ” Stars”. It learns the data based on similarities in properties such as particular shape edges and groups them accordingly.
Key characteristics include:
- No Labels: the data does not consist of any predefined categories or outcomes.
- Pattern Discovery: Focus on determining the hidden relationships or structures
- Data-Driven Insights: Generates insights directly from the data, often giving correlations and clusters that were unknown previously.
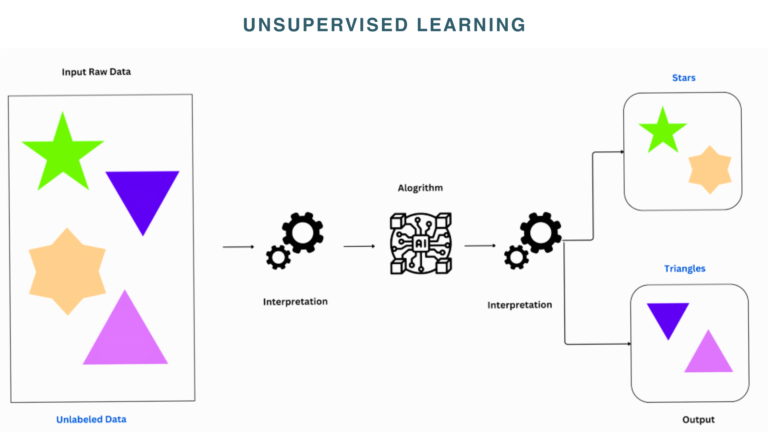
How Unsupervised Learning Works?
As we know, it works on unstructured data which means outcomes are also not defined. The unsupervised learning algorithms explore the data by themselves, analyze grouping or patterns, and give output on their own. Here’s how the process works:
Step 1: Data Exploration
- The first phase includes getting raw, unlabeled data such as customer purchase records.
- After getting the raw data, the algorithms start analyzing the dataset to find out hidden patterns, relations, or structures.
Step 2: Pattern Identification
- In this stage, the algorithm groups data based on similarities using mathematical and statistical techniques.
- Such as grouping customers with the same purchasing behavior.
Step 3: Insight Generation
- The last step is coming up with the output.
- Once it recognizes patterns or structures, the algorithms give results that can be interpreted for actionable insights.
- For example, the algorithm finds clusters of customers with the same habits, such as frequent buyers of electronics or occasional buyers of clothes.
Types of Unsupervised Learning
Unsupervised learning is also further divided into three types. Let’s discuss each one individually.
1. Clustering
In clustering, the dataset is divided into distinct groups or you can say clusters, where data is included based on the shared and similar characteristics.
Key Features:
- Includes on predefined labels
- Use similar measures (e.g, distance metrics)
- Common methods include K-Means, Hierarchical Clustering, and DBSCAN.
Real-World Examples:
- A common example includes grouping customers based on their purchasing habits to make targeted marketing campaigns.
- Moreover, grouping genes with the same expression profiles to understand their functions.
2. Association Rule Learning
This approach works by finding relationships or dependencies between variables in large datasets to identify hidden patterns.
Key Features:
- Often used in transaction databases
- Work on the if-then rule, such as “if X, then Y”
- Common algorithms include Apriori and Eclat.
Real-World Examples:
- This technique is beneficial in market basket analysis.
- For a personalized recommendation on e-commerce websites.
3. Dimensionality Reduction
Dimensionality reduction involves reducing the number of variables in data while also maintaining its essential structure and patterns.
Key Features:
- For visualizing high-dimensional data
- Reduce computational complexity and overfitting
- Common techniques include Principal Component Analysis (PCA) and t-SNE ((t-distributed Stochastic Neighbor Embedding).
Real-World Examples:
- The common usage is in image compression to store and analyze images efficiently.
- It is used to simplify complex datasets for intuitive 2D or 3D visualization.
Popular Algorithms Used in Unsupervised Learning
The most popular algorithms that are extensively used in unsupervised learning are given below:
- K-Means Clustering: These algorithms group data into a pre-existing number of clusters depending on their similarities. Moreover, each of the clusters is pivoted to a calculated mean.
- Hierarchical Clustering: In this, algorithms usually work by building a hierarchy of clusters such as joining smaller clusters or dividing larger ones. Thereby, it is showcased as a dendrogram.
- Principal Component Analysis: The algorithm works by reducing the dimensionality of the data by changing it into the principal component. This information can hold the most significant information.
- Autoencoders: These are neural networks that are built to learn efficient data representations by decoding and reconstructing the input information.
What are the Key Applications of an Unsupervised Learning System?
Not to forget, unsupervised learning also has diverse use cases. In this section, we will discuss the most common applications of this type of learning.
1. It is Most Commonly Used in Customer Segmentation
Well, businesses also struggle to segment audiences for targeted campaigns. This can be done through customer segmentation which is backed by unsupervised learning. Businesses can use this approach to divide their audience into different segments based on characteristics such as demographics, purchasing behavior, or search history.
For example, dividing customers into frequent, occasional, or first-time buyers to give personalized offers in e-commerce.
2. It Can be Used for Anomaly Detection
This type of learning can also be applied to find outliers or strange patterns in datasets that may show errors, fraud, or uncommon events.
The most common example is spotting abnormal transactions in a bank’s data to avoid financial fraud.
3. It Works Best for Recommendation System
You must be aware of the recommendation system. These systems use unsupervised learning to determine user preferences and recommend products, services, or content.
For example, streamlining platforms such as Netflix grouper users based on similar vexing habits to suggest movies and shows.
Advantages and Disadvantages of Unsupervised Learning
Every technology has some plus points and negative ones. Unsupervised learning has wide applications but it has major drawbacks which you need to be careful about.
Benefits | Challenges |
It efficiently processes large amounts of unlabeled data | Highly complex which hinders the accuracy and effectiveness of the system |
Helps easily in dimensional reduction | Output results often lack accuracy |
Highly capable of analyzing previously unknown patterns in data | Time-consuming as users need a great time to interpret and label the classes |
It is great for exploratory data analysis and gaining valuable insights | Computationally intensive for large datasets |
How to Choose Between Supervised and Unsupervised Learning
Choosing between supervised vs unsupervised machine learning techniques depends on several factors such as the nature of data, your goals, and available resources. If you want to effectively implement these approaches, it is critical to know the criteria for selecting.

Step 1: Determine the Nature of Dataset
First look for the nature of your data.
- If it consists of labeled data, supervised learning is a better choice.
- On the other hand, if data is unlabeled or unstructured, unsupervised learning should be your way to go.
Step 2: Finalize your Goals
Look for the outcomes you are expecting.
- If your goal is to have predictions or classification, such as separating spam emails, opt for supervised learning.
- Moreover, unsupervised learning can be a good option when the goal is to explore or discover hidden information in data like customer segmentation
Step 3: Look for the Available Resources
- Supervised learning needs more time and resources to categorize data, making it more expensive but highly accurate.
- On the other hand, the latter saves resources by eliminating the need for labeled data, but the results may be less accurate.
Can Supervised and Unsupervised Learning Be Used Together?
Now, you might be thinking, can supervised and unsupervised learning be used together? Definitely! You can use combined or hybrid approaches to use the strength of supervised and unsupervised learning models in your systems.
Moreover, these combined approaches often result in better performance and more effective solutions. Here are some common hybrid approaches:
Semi-Supervised Learning
Semi-supervised learning is one of the best approaches. It usually combines the strengths of both supervised and unsupervised learning. Generally, this approach takes a small amount of labeled data and a large amount of unlabeled data. The end goal is to make labeling data less costly or less time-consuming.

Reinforcement Learning
The next approach is reinforcement learning. Generally, it works independently, but somehow it uses several elements of supervised and unsupervised learning. In this learning, a system learns by interacting with the environment and greeting feedback through rewards and penalties.
Practical Implementation of Hybrid Approaches
Here are some real-world examples of hybrid approaches that make it clearer to you.
- In image recognition systems, both supervised and unsupervised learning are used. The latter groups images based on similar characteristics, while the first one is used to classify them accurately.
- Additionally, semi-supervised learning is used in text classification. It can be used to classify text data with few samples and allow the system to use the information to implement it on a large number of unclassified data.
- Furthermore, the reinforcement learning concept is widely used in autonomous vehicles such as helping the vehicle learn driving strategies through rewards and penalties.
Conclusion
In conclusion, it is crucial to understand the basic difference between supervised and unsupervised learning to select the right approach and make a highly responsive system. Supervised learning excels when you’re dealing with labeled data. On the other hand, unsupervised learning thrives when you come across unlabeled data.
In short, both approaches have their own set of strengths and limitations, but hybrid approaches can be used if you want to add the essence of both worlds. Ultimately, choosing the right approach depends on several factors such as the nature of the data, selected goals, and available resources.
Our team has researched thoroughly and come up with this article to help you understand these techniques and make informed decisions to use them efficiently in the real world.
FAQs
What is the difference between supervised & unsupervised machine learning?
- The most common difference is that the first one deals with labeled data while the other can help analyze patterns in unlabeled data.
What is an example of unsupervised learning?
- Grouping customer data based on their purchased history and shared characteristics without any pre-existing labels can be an example of unsupervised learning.
Is ChatGPT supervised or unsupervised?
- Interestingly, ChatGPT uses a combination of supervised learning and reinforcement learning.
Is CNN supervised or unsupervised?
- Convolutional Neural Networks (CNNs) use a supervised learning approach. For instance, they are used in image classification.
Why It is Essential to Know About Different ML Algorithms?
- Have a look at our guide on “Understand Different Machine Learning Algorithms in 2025“